I recently read Atul Gawande’s ‘The Checklist Manifesto – How to Get Things Right’. It’s a gripping read. Dr. Gawande tells us how checklists can help manage complexity, and he uses examples from varied disciplines – healthcare and aviation to name a couple – to make his case.
Checklists provide a cognitive net. They catch mental flaws inherent in all of us – flaws of attention and memory and thoroughness.
 I think checklists can be a great way to streamline what we do as data scientists. Making sense of real world data and drawing dependable conclusions is difficult. Many hobgoblins await to trip us up. I’d like to show you a couple of subtle traps I’ve encountered in my work as a data scientist:
I think checklists can be a great way to streamline what we do as data scientists. Making sense of real world data and drawing dependable conclusions is difficult. Many hobgoblins await to trip us up. I’d like to show you a couple of subtle traps I’ve encountered in my work as a data scientist:
Data Leakage
Data leakage occurs when we accidentally use data to train our models that would not be available when making real predictions. This can happen in a variety of ways:
- The prediction results accidentally leak into the training and test data due to sloppy data preparation.
- We neglect data collection delays in an operational environment.
- Information from the future leaks into the past.
According to Kaggle, identifying and exploiting data leakage is a very common way to win data science competitions!
We can see real life examples of data leakage when building smart meter forecasts. Here’s what a typical smart meter load profile looks like.

As a naive illustration, let’s say we train a simple exponential smoothing model to forecast the power consumption.
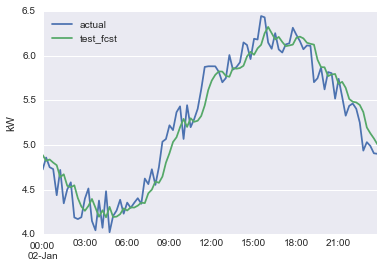
We see a low error (RMSE) of 0.188. Let’s deploy to production!

Wait a minute, what’s going on here? Our production forecast has dropped close to zero! Turns out smart meter data is collected through wireless mesh networks, which are slow. There’s a delay before data is available in a live production environment. The exponential nature of the forecast discounts old meter readings, so we end up with near zero results.
Once we understand this quirk in the data, we can think of a hybrid approach where we combine a linear regression model with an exponential smoothing model – making it less sensitive to data delays. However, our goal should be anticipate these issues way ahead of time – avoid angst and slipped deadlines. Not to mention embarrassment!
Base Rate Neglect
Let’s say we came up with an amazing fraud detection algorithm. We deployed it to our test environment and collected the transactions it flagged as fraudulent. To our dismay, we saw that most of them looked legit.
How could that have happened?
We fell into the base rate trap. Fraudulent transactions might be on the rise, but they are still relatively rare. Which means that the effect of false positives will dominate our results.
To illustrate, let’s say 1 out of every 1000 transactions are fraudulent, and our model has a true positive rate of 99% and a false positive rate of %1. What does that mean?
| Fraudulent Transactions | Non Fraudulent Transactions | Total | |
|---|---|---|---|
| Flagged Fraud | 99 | 999 | 1,098 |
| Flagged Not Fraud | 1 | 98,901 | 98,902 |
| Total | 100 | 99,900 | 100,000 |
Out of every 100,000 transactions, there are 100 fraudulent and 99,900 legitimate transactions. Our model identifies 99 of the fraudulent transactions correctly. But it also snags 999 legitimate transactions, which means that only 10% of our results are useful! The problem is we don’t know which 10%.
Why was our model so off? Biased sampling during the data exploration phase is a likely culprit. This could easily happen in larger organizations, where IT policies prevent direct access to all transaction data. Let’s say a well meaning DBA gave us data samples skewed in favor of fraud positive data, to make it easier to find common patterns. If we then fitted our model on the same skewed data sample, using default learner settings that treat false positives and false negatives equally, we can explain how we landed in this pickle. What we should have done instead is to train our model on a representative data sample, and adjust learner defaults to penalize false positives more. But we would only have known that by asking the right questions early on.
Obviously, I don’t intend to make a comprehensive list here. Every industry and application domain will have a different set of pitfalls to watch out for. However, what I hope I’ve accomplished is to convince you to make your own checklist.
What’s on your checklist? I would love to hear your thoughts!
