In my last post, we saw how chasing unicorn data scientists can be an exercise in frustration. I made a case for providing data science training to your current team members who have the right domain knowledge and aptitude. But what do you do when you absolutely need to expand your team? How do you hire while competing against offers from tech gorillas like Google and Facebook?
The parallels with Moneyball are uncanny. You’ve read the Michael Lewis book on how the Oakland A’s put together a competitive baseball team despite having a smaller budget than nearly every other MLB rival. They shunned conventional wisdom and used innovative statistical analyses to find undervalued players. The key was finding players who would perform really well together as a team – a major win for data science before data science was a thing.
Can we catch some inspiration from Billy Beane’s methods?
Let’s find some data to explore
The most readily accessible is LinkedIn data – what skills are people showcasing when positioning themselves as data scientists? I pulled data for five hundred data scientist profiles and ran the numbers.

Here’s a chart of the top twenty most frequently occurring skills – notice how you find Python, Machine Learning, R, Data Analysis, Statistics and SQL in over 50% of profiles. But that doesn’t mean that the same 50% of profiles have all of those skills.
Let’s have some fun and dig a little deeper. Can we find patterns of how skills cluster together? Can we discern career paths that lead to data science?
Finding patterns in the data
Here’s the approach I’ll take. Let’s assume for a moment that the skills we’ve found are independent of each other. Then Bayes theorem tells us that the expected probability of finding any skill pair in a profile is equal to the product of the individual probabilities for those two skills. Any deviation from that expectation indicates a positive or negative interaction effect. For example – Python and Machine Learning are listed in 70% and 66% of profiles respectively, so we should expect to find them listed together in 46% of profiles. But the data shows that they are listed together in 54% of profiles, which indicates a positive clustering effect between them. Let’s visualize this better with heatmaps showing the deviation from the expected occurrence rate for every skill pair.

The first heatmap shows skill pairs that occur together more frequently than expected. For example – Hadoop and Big Data, R and Statistics, Python and Machine Learning, Java and Hadoop.
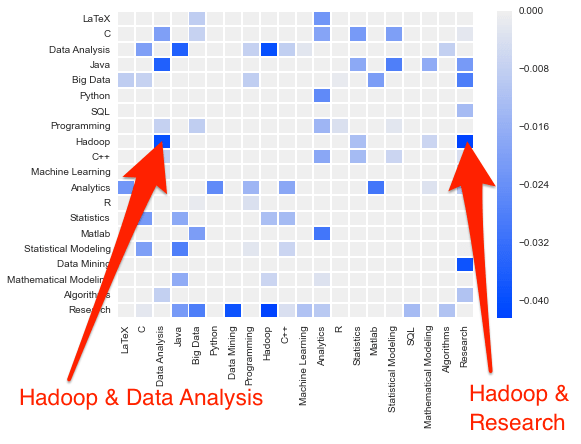
The second heatmap shows skill pairs that are less frequent than we’d expect, like Hadoop and Research. This means that a candidate with a research background is less likely to be familiar with the Hadoop tech stack.
Part of the clustering effect is due to variations in nomenclature for synonymous skills. For example, statisticians tend to use the term Data Analysis, whereas Hadoop users prefer to say Data Mining. Still, we can see distinct backgrounds that lead people on the path to become data scientists. Some examples:
- Big Data Engineer (Hadoop, Big Data, Java)
- Software Engineer (Python, Algorithms, SQL)
- Statistician / Analyst (R, Statistics, SQL)
Expand your search
Why don’t you expand your search to include people from these feeder backgrounds? Studies show that 52% of data scientists have earned that title within the last four years. Which means there is no reason to limit yourself to the self identified pool of 11,400 data scientists.

You can get creative when combining skills on the team – in the example above, adding a QA engineer enhances the overall data engineering skills of the team. How? Part of her previous roles involved writing scraping scripts to automate testing of web applications. She can put those skills to good use finding creative ways to collect high impact data.
You have more options than you think.
Benefits
What are the benefits of such an approach?
- You can be discriminating when it comes to domain knowledge – you can look for candidates in your industry vertical.
- By bringing in people from diverse backgrounds, you will encourage effective team communication and questioning of assumptions.
- You will be hiring for strengths and not lack of weaknesses.
- You’re less likely to compete directly against offers from Silicon Valley heavyweights, making it a lot easier on your budget.
But how do you know if someone without ‘Data Scientist’ in their title will be a good fit? Apart from solid technical skills in their domain, you will need to gauge if they have the right temperament. I’ll address some of those key data science mindsets in my next post.
Stay tuned!
